




Artificial Intelligence (AI), and to a lesser extent, Machine Learning (ML) and Deep Learning (DL) are three popular terms you hear frequently. And for good reason – they represent a major step forward in how computers can be used to solve problems. Read Part 1, Understanding Data.
When Google DeepMind’s AlphaGo program defeated 18-time world champion Lee Sedol in March 2016, all three terms were used by the media to describe how DeepMind won. But, although these terms are often used interchangeably, they are not the same. Instead, you can think of AI, ML, and DL as a set of Russian dolls nested within each other, with the largest, outermost doll being AI and the smallest, innermost doll being DL (leaving ML in the middle).
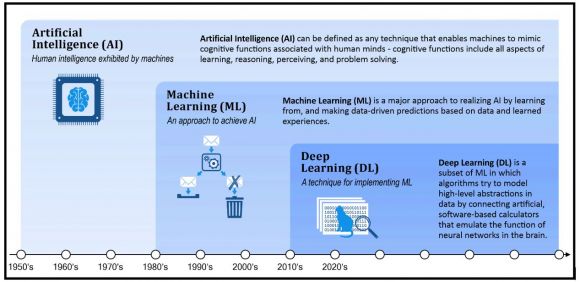
Figure 1: Artificial Intelligence, Machine Learning, and Deep Learning
AI is the all-encompassing concept that’s concerned with building smart machines that can perform tasks that normally require human intelligence. ML refers to a broad set of techniques that give computers the ability to “learn” by themselves, using historical data and one or more “training” algorithms, instead of being explicitly programmed. And DL is a technique for implementing ML that relies on deep artificial neural networks to perform complex tasks such as image recognition, object detection, and natural language processing. (Neural networks are a set of algorithms, modeled loosely after the neural networks found in the human brain, that are designed to recognize hidden patterns in data.)
While it has garnered a lot of attention recently, Artificial Intelligence is not new. It has been a part of our imagination since Alan Turing published the paper "Computing Machinery and Intelligence" in 1950. And it has been part of our vocabulary since Assistant Professor of Mathematics at Dartmouth College, John McCarthy used the term to describe a new field of research dedicated to "thinking machines" in 1955. The dream of many early AI pioneers was to be able to construct complex machines – with the aid of computers – that possess the same characteristics of human intelligence. And, it is this concept, now referred to as “General AI,” that has been sensationalized by movies like “2001: A Space Odyssey“ and ”The Terminator.” While we are nowhere near being able to deliver this type of AI today, we are at a point where computers are capable of providing “Narrow AI” (or “Modern AI”), which is a term that is used to describe technologies that can perform specific tasks – especially repeatable tasks – as well as, or better than human beings. This type of AI might be used to classify images on a service like Pinterest, or to recommend movies a streaming service subscriber might be interested in viewing.
In reality, AI can be as simple as a set of IF-THEN programming statements or as complex as a statistical model that is capable of mapping raw sensory data to symbolic categories. (IF-THEN statements are nothing more than a set of rules that have been explicitly coded by a human programmer; in fact, multiple IF-THEN statements used together are sometimes referred to as rules engines, expert systems, symbolic AI, or simply GOFAI – an anacronym for Good, Old-Fashioned AI.) However, some argue that when a computer program designed by AI researchers succeeds at doing something complex – such as beating a world champion at chess – this doesn’t really demonstrate AI because the algorithm’s internals are well understood by the researchers. Instead, true AI only refers to computer systems that have been designed to be cognitive; that is, to be aware of context and nuance and to make decisions that are the result of a reasoned analysis.
Over the past few years, and especially since 2015, interest in and use of Narrow AI has exploded, primarily because of the increased computing capabilities of systems that make parallel processing ever faster, cheaper, and more powerful. And because of the simultaneous convergence of practically infinite storage and a flood of data of every type – transactions, images, videos, text – you name it.
Machine Learning is an application of AI that provides computer systems with the ability to automatically learn and improve from experience. In fact, one aspect that separates ML from other types of AI (such as rules-based engines) is its ability to modify itself when exposed to more data. The “learning” part refers to the fact that finely tuned algorithms are continuously trying to optimize along a certain dimension; typically, to minimize error or to maximize the likelihood some type of prediction will be correct.
For many years, one of the best application areas for ML had been computer vision, although a great deal of hand-coding was still required. Programmers would build feature extractors like edge detection filters so applications could identify where an object feature started and stopped. Shape detection algorithms were also created to help classify specific numbers in a string. The resulting technology was then used to read numbers at the bottom of a check when making a deposit. Or, to redeem gift cards by scanning a code printed on the back of the card.
Deep Learning is a subset of ML that relies on a complex set of algorithms that are designed to identify hidden patterns in data. These algorithms help group unlabeled data according to similarities found among sample inputs, and they can classify data when they have been given a labeled set of data to train on.
Normally, the term “deep learning,” refers to the use of deep artificial neural networks. In this case, “deep” is a technical term that refers to the number of layers that are found in the neural network itself – a shallow network will have one hidden layer while a deep network can contain hundreds. Multiple hidden layers allow deep neural networks to learn features of data in a so-called feature hierarchy, where simple features (for example, pixels) recombine from one layer to the next, to form more complex features (for instance, lines). Neural networks with many layers pass data (features) through more mathematical operations than those with fewer layers, and therefore are computationally intensive to train. The framework of DL is a neural model of understanding that is built using weights and connections between data points – often millions – discovered in the training data set used.
Prior to 2010, very little work was being done in this area because even shallow neural networks are extremely compute-intensive. It was only when three forces converged – the availability of immense stores of labeled data; the invention of new deep learning algorithms; and cheaper, more powerful CPUs (central processing units) coupled with the intense performance of GPUs (graphics processing units designed to render images, animations, and video for a computer's screen, that are also exceptional at performing the matrix-matrix multiplication that is often utilized by deep learning) – that deep learning moved from research papers and laboratories to real world applications. Now, the way in which deep learning can be adopted and used has become a critical strategic consideration for many organizations.
For more information, refer to this article which was the inspiration and source for much of this narrative:
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/.
The building blocks of AI, ML, and DL
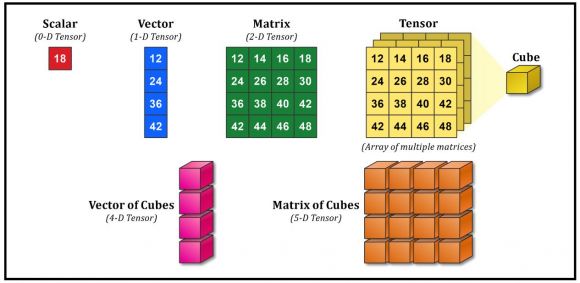
Figure 2: Building blocks of AI
While data is the foundation of AI, ML, and DL, linear algebra, probability, and calculus are its language. And the two mathematical entities that are of the most interest are vectors and matrices. Why? Because they are simplified versions of a more general entity that serves as the basic building block of modern ML and DL – the tensor.
To understand what a vector is we must first understand what a scalar is. A scalar is a physical quantity that is represented by a real number. Some examples of scalars include speed, volume, mass, temperature, and pressure. A vector, on the other hand, is a quantity that is defined by two scalars. One of the primary use cases for vectors is to represent physical quantities that have both a magnitude and a direction. Examples of vector quantities include position, force, velocity, acceleration, and momentum.
Vectors are members of objects known as vector spaces, which can be thought of as a collection of all possible vectors of a specific dimension. In ML and DL, vector spaces (often referred to as feature vectors) are used to mathematically represent numeric or symbolic characteristics (or features) of an object. One example of a feature vector many people are familiar with is the RGB (red-green-blue) color palette. This feature vector is used to describe distinct colors according to how much red, green, and blue they contain. Feature vectors are used widely in ML and DL because they offer an effective and practical way of representing data objects, numerically.
A matrix (plural matrices) is a set of numbers, referred to as elements or entries, that have been arranged in rows or columns to form an array. It’s possible to add and subtract matrices of the same size, multiply one matrix with another (provided the matrix sizes are compatible), and multiply an entire matrix by a constant. Matrices can be used to compactly write and work with multiple linear equations, simultaneously. Because a matrix can have just one row or one column, a vector is also a matrix. So mathematically, the rules that work for matrices also work for vectors.
In mathematics, a tensor is an algebraic object that describes a multilinear relationship between sets of algebraic objects related to a vector space. Objects that tensors can map between include, but are not limited to, vectors, scalars, and other tensors. In simpler terms, a tensor is a container that can hold data in multiple dimensions. They possess an order (or rank), which determines the number of dimensions in an array that are required to represent them. Technically, a scalar is a zero-dimensional (0D) tensor that has a rank of 0, a vector is a one-dimensional (1D) tensor that has a rank of 1, and a matrix is a two-dimensional (2D) tensor that has a rank of 2. But to avoid confusion, the term “tensor” is generally used to refer to tensors that have three dimensions, or more.
Although a tensor is often thought of as a generalized matrix that ranges from zero to N dimensions, it’s really a mathematical entity that lives in a structure and can interact with other mathematical entities. If something transforms the other entities in the structure in a regular way, the tensor must obey a related transformation rule. Thus, you can think of a tensor as a team player whose numerical values shift along with those of its teammates when a transformation is introduced that affects them all.
So, how are tensors used with ML and DL? In the previous article in this series, we saw that AI, ML, and DL cannot exist without data and that modern data is often multi-dimensional. Tensors play an important role by encoding multi-dimensional data in a way that it can be easily used by ML and DL models. If you think of an image as being represented by three different fields – width, height, and depth (or color), it’s not hard to visualize how an image might be encoded as a 3D tensor. However, ML and DL models often work with tens of thousands of images. So, this is where a fourth field or dimension – sample size – might come into play. Thus, a series of images can be stored in a 4D tensor which, as you can see in Figure 2, is basically a vector of cubes. This representation allows problems that require the analysis of large volumes of image data to be easily solved.
As was pointed out earlier, a specialized electronic circuit known as a graphics processing unit (GPU) is extremely good at performing matrix mathematics. Therefore, GPUs are frequently used to greatly speed the processing needed for ML and DL matrix mathematical operations.
The ML/DL workflow
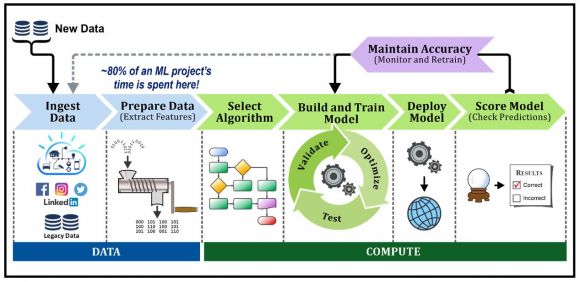
Figure 3: The Machine Learning/Deep Learning workflow
Data scientists build, train, deploy, and use ML and DL models by going through the steps illustrated in Figure 3. And performing these steps can take a significant amount of time (some steps more than others), as well as computational resources. Let’s take a closer look at each workflow step.
- Ingest data – Data ingestion refers to the process of accessing and importing data for use. Typically, data ingestion consists of three steps: extract (taking data from its current location), transform (cleansing and normalizing the data), and load (placing the data in a central location – often a relational database – where it can be easily accessed). Enterprises usually have an easy time with extract and load. However, the transformation step can be challenging because data can come from anywhere: a relational database management system like IBM Db2, web logs, application logs, social media sites, live streams, and so forth. And it can be stored in a wide variety of formats.
Data can be ingested in one of three ways: batch, real-time, and streaming. Batch is an efficient way of processing large volumes of data that is generated by a sizeable set of transactions, over time. Real-time data, on the other hand, demands continual input, process, and output. And, with steaming, data is immediately processed off incoming data flows like Apache Spark or Kafka. This form of data ingestion is frequently used for predictive analytics.
- Prepare data – ML models are trained on data that has been analyzed and categorized from thousands to millions of individual data points. And, preparing all that data for use is often one of the biggest challenge organizations face, not only in the complexity of the work required, but also in the amount of time it takes to convert the data into a usable format. In fact, many data scientists claim that over 80% of their time is spent performing this crucial task. Why is so much time spent here? Because, in most ML and DL implementations, this is a highly manual and serial process. Work done here involves building connections to data sources, extracting data to a staging server, creating scripts in programming languages like Python and Scala to manipulate the data after it is staged, removing extraneous elements, breaking large images down to small “tiles” so they will fit in GPU memory, and so forth. And it’s a process that is very much prone to error.
- Select the algorithm – This is where the algorithm that will be used to build the model is chosen. (We’ll look at what models are next.) Often, there can be several algorithms to choose from and this stage of the process can require a significant amount of trial-and-error testing before the best algorithm is chosen.
- Build, train, optimize, test, and validate the model – This stage of the process is extremely compute-intensive and requires the highest amount of domain knowledge. Work done here involves developing initial models, setting model hyperparameters, and adjusting/tweaking model parameters to get to the highest level of accuracy possible. There is both art and science in this process, and it’s at this stage where an organization’s gap in data science and ML/DL skills causes the most pain.
- Deploy and score the model – ML models initially train on historical data, and then inference (score) their predictions against incoming data, in real-time. To score in real-time, trained models need to be deployed close to where data originates, sometimes as stand-alone pieces of logic, but more often as parts of other programs. (A more accurate analysis means better insights are realized faster.) This stage of the process is where organizations use ML to build new businesses or add value by finding a more precise inference.
- Maintain model accuracy; ingest and re-train on new data – After a model has been deployed, it must be continuously monitored – and in some cases be re-built and/or re-trained – to ensure its quality doesn’t degrade over time. Therefore, this is the step in the process that closes the loop and ensures that models used in production maintain a high level of accuracy throughout their lifecycle.
What is a model?
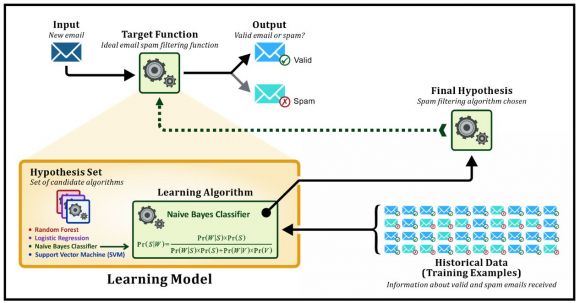
Figure 4: A learning model
Although a significant amount of time is spent obtaining and preparing data for ML and DL projects, as we saw earlier, the bulk of the ML/DL workflow is focused on building, training, deploying, and monitoring “models.” But, if you’re not a data scientist, you may not be familiar with just what a learning model is. The illustration shown in Figure 4 attempts to remedy that.
The essence of ML and DL can be boiled down to three things:
- Historical data is available
- Some type of pattern exists in this data
- Once the pattern has been identified, it can be used to make predictions about future actions or behaviors
If you’ve ever used Yahoo or Google Mail, you’ve probably seen a folder named “Junk” or “Spam.” And, if you’ve looked inside that folder, chances are you found it contained email messages you didn’t really want to receive. Furthermore, if you continuously throw away messages that come from the same sender without reading them, at some point you may discover that these messages are automatically placed in the Junk/Spam folder on your behalf. It’s a good bet that an ML algorithm was used to create the model that performs these “spam filtering” tasks. So, let’s use this example to illustrate what a machine learning model is.
As you can see in the illustration shown in Figure 4, a learning model consists of two components – a set of algorithms a data scientist believes could be used to find a pattern that exists (in this case, a pattern that indicates whether an incoming email message is spam) and the actual algorithm that’s chosen from this set, based on the probability that it will do the task it’s expected to do once it has been trained.
ML models can be thought of as having two phases: a training phase and a prediction or scoring phase. Going back to our email spam filtering example, if you look at a typical spam email message, you might find words like “sweepstakes,” “loan,” or “Viagra.” On the other hand, these words probably don’t appear very often in emails most would consider valid. During the model training phase, we might tell our hypothesis set of algorithms to look at historical data and note the probability with which each of these words appear in both spam and valid email messages.
For example, if we know that 6,000 out of 10,000 messages in our training data set are spam and if the word “sweepstakes” appears in 2,000 emails that are spam and 10 emails that are valid, the probability that a spam email message contains this word is 0.333 (2000/6000 = 0.333). And the probability that this word will appear in a valid email message is 0.0025 (10/4000 = 0.0025). Thus, if an incoming email message contains the word “sweepstakes”, the probability that the message is spam is much higher than the probability that the message is valid.
As part of the model training phase, we would use every algorithm in our hypothesis set to calculate these types of probabilities and the algorithm that proves to be the most accurate would be chosen as our final hypothesis algorithm or model. A test data set would then be used to validate our model selection. (If possible, we would compare the model’s predictions with “ground truth” data to determine its accuracy.) Of course, an email message consists of several words so this process would need to be replicated using a much larger vocabulary, but you get the idea. The goal is to identify the hypothesis algorithm that has the highest probability of producing the desired output when the input provided is unknown.
Stay Tuned
In the next part of this article series, we’ll explore how data is prepared for ML and DL, as well as for ML and DL model training.
LATEST COMMENTS
MC Press Online